From Plato to Pluto, the hundreds of subjects taught at UCLA cover much of the knowledge scholars accumulated over time. And with the geography of UCLA as a guide, we may even group these hundreds of subjects into the North and South campuses. But this division alone fails to inform us about the finer relationships between academic departments.
The good news is that the UCLA Registrar provides valuable information that allow us to more precisely determine what each department is about. Using course descriptions as well as departmental objectives, we apply a variant of the word2vec algorithm – a machine learning model that can capture the semantic meaning of words – to quantify each department as a list of numbers. These numbers provide a blueprint for analyzing the links and clusters that relate one department to another.
Re-mapping UCLA departments
We can visualize this analysis as a scatter plot and locate each department on a “map.” A few departments are labeled, but feel free to hover over any point.
Our model computes 200 dimensions for each department, but we reduce it down to a 2D chart using a dimensionality-reduction tool called t-SNE. While the plot preserves clusters that form in the original, high dimensional space, the visual distances between points don’t convey much information.
5 Most / Least Similar Departments
Pick a subject and see which 5 other subjects are most and least like it:
5 Most Similar
5 Least Similar
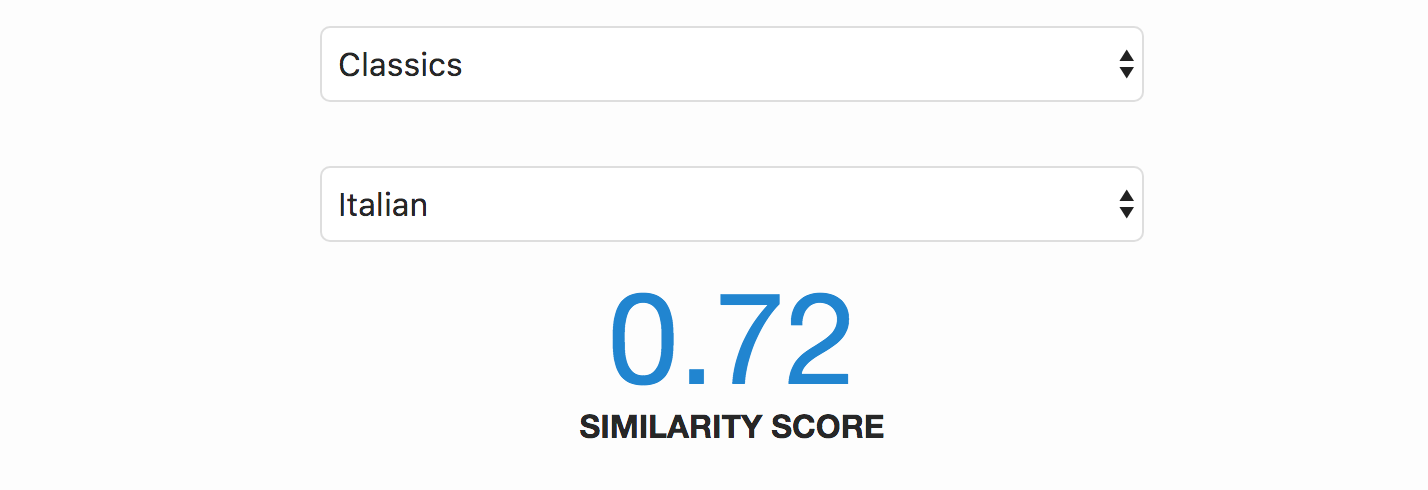
Similarity Score: Cosine similarity ranges between -1 to 1. As a rule of thumb, a score greater than 0.5 indicates similarity, and a score around or less than 0 indicates a lack of similarity.
Compare any 2 departments
Pick and compare any two subjects.
(Which two? Your old major and your current major, what you and your significant other study, double majors, etc.)
Grouping departments
We can group together departments that are similar. As it turns out, the algorithmically-generated clusters match our intuition pretty well. They even manage to reproduce the North-South campus divide UCLA students are intimately familiar with.
North Campus
Group 1 (“Perform”)
Dance; Design
Media Arts; Ethnomusicology; Film and Television; Music; Music History; Theater
Group 2 (“Speak”)
Art History; Ancient Near East; Comparative Literature; Chinese; Classics; English; English Composition; French; German; Italian; Japanese; Korean; Linguistics; Philosophy; Scandinavian; Spanish
Group 3 (“Society”)
Art; Anthropology; Asian American Studies; Communication Studies; Chicana and Chicano Studies; Environment; Education; Gender Studies; General Education Clusters; Geography; History; Political Science; Society and Genetics; Sociology
South Campus
Group 4 (“Capital”)
Economics; Management
Group 5 (“Life”)
Ecology and Evolutionary Biology; Life Sciences; Molecular, Cell, and Developmental Biology; Microbiology, Immunology, and Molecular Genetics; Neuroscience; Psychology; Physiological Science
Group 6 (“Compute”)
Computer Science; Electrical Engineering; Mathematics; Program in Computing; Statistics
Group 7 (“Matter”)
Astronomy; Atmospheric and Oceanic Sciences; Chemical Engineering; Chemistry and Biochemistry; Civil and Environmental Engineering; Earth, Planetary, and Space Sciences; Mechanical and Aerospace Engineering; Physics
Other applications
So far we’ve made comparisons that mostly match our intuition, and the model “works” only because the results don’t deviate much from common sense. Here are a few ideas for applying the model to other uses:
Departments gain or lose students whenever students switch between majors. Because the relevant data are subjected to privacy protections, we can only make an educated guess of students’ major-switching patterns. First, we could use publicly available information to compare the number of students who are admitted into a major to the number of students who graduate from that major. The difference hints at how much a department has gained or lost students. Then, by assuming students are more likely to switch into other similar departments that have gained students, our model could help with guessing how students switch between majors.
The gender / racial composition of departments is a familiar topic, but demographic data are rarely collected. Consider the hypothetical case where we don’t know the demographics of Sociology students. We might infer the missing information by doing a weighted average of the demographics in departments for which we have information; and the weights depend on how similar every other department is to Sociology, if we assume similar departments have similar people.
Roommate assignments can benefit from considering each applicant’s academic interests. Data on how departments are related could provide additional information for the assignment process. Keep in mind that we don’t need to assume students who study similar subjects make for better roommates. If surveys show that people with opposite interests are less likely to have roommate issues, it’s something the model can help with as well.
Data
In this project, we want texts that represent the essence of academic subjects. For every department, we use the course descriptions of all the classes offered by that department. Many departments also publish a “Scope and Objectives” statement, which we incorporate as well.
Course Catalog
The course catalog reflects the breadth and depth of subjects in the academic world, and how they are taught at UCLA. Crucially, keywords of topics that are taught in classes can capture the intellectual linkages between disciplines. Course descriptions also sometimes refer to pre-requisites in other departments or classes that are cross-listed in multiple departments. These links provide clues into the organizational linkages between subjects at UCLA.
However, course descriptions are sparsely worded and usually contain a listing of keywords rather than fully expressive sentences. They can limit the model from fully capturing the semantics.
A typical course description
Departmental Objectives
In contrast to course descriptions, departmental objectives are written in full sentences and paragraphs that better express how each department positions itself, thereby providing contextual information which are missing from the less expressive course descriptions.
The Linguistics departmental objective
Model
Department <-> Document
For each department, we create a document that combines the course descriptions of all the classes under that department, and if applicable, its objective statement. Quantifying the relations between departments is then a matter of modeling the relations between these text documents.
A Language Model
A landmark achievement in natural language processing is the word2vec model, which infers the meaning of words by looking at where they are used. For example, by observing how “king” and “queen” are often surrounded by the same words (think “castle” or “govern”), the model guesses that they refer the same concept (ie. head of monarchy). The model also learns how they differ in gender by noting how they are used with different gender pronouns.
To learn semantic meanings, word2vec trains a two-layer neural network to predict which word is used given its surrounding words. However, the predictive task is tangential, and researchers are instead interested in the by-product – how each word contributes to the predictive task (ie. the word vectors). By comparing word vectors, we can then examine the relations between words.
We use a paragraph vector model that is similar to word2vec in spirit but examines language at the document level. The gensim implementation is used and it returns a 200-dimensional vector for each department’s texts.
Clustering
We also apply the K-means algorithm to form 7 groups of departments that have document vectors which are close together in Euclidean distance.
AUTHOR
Tyson Ni
Data Viz Apprentice
Tyson likes telling stories with data. Feel free to send him feedback, data, or story ideas.